
Contents
Coursera Professional Certificate – IBM Data Engineering

➔
★★★★★ 4.5 / 5
The IBM Data Engineering Professional Certificate course is highly recommended for individuals aspiring to enter the data engineering field. With its comprehensive syllabus, practical exercises, and industry-aligned content, it provides a solid foundation for aspiring data engineers. While there are some areas for improvement, such as more interactive elements and detailed explanations, the course offers excellent value for money and equips learners with essential skills for real-world data engineering tasks.
Pros
- Broad range of data engineering topics
- Hands-on projects and labs
- Taught by IBM professionals
- ACE-recommended for academic credits
Cons
- Challenging without prior programming experience
- Lack of interactive elements
- Time-consuming
Get 40% off your first year of Coursera Plus Annual — unlimited access to 10,000+ courses (new subscribers only)
In the digital age, data has become the lifeblood of businesses, and the ability to manage and interpret this data is a highly sought-after skill. IBM Data Engineering, a Professional Certificate offered on Coursera, is a comprehensive program designed to equip learners with the knowledge and skills necessary to thrive in the field of data engineering. This review will focus on the specifics of the program, providing an in-depth analysis of its content, delivery, and value for money.
Overview of the IBM Data Engineering Professional Certificate
The IBM Data Engineering Professional Certificate is a self-paced online program comprising 13 courses. As the course is recommended by ACE, learners can earn 12 college credits upon completion. It is designed to provide learners with a solid foundation in data engineering, covering a wide range of topics from Python programming to relational databases and NoSQL databases. The program also includes hands-on labs and projects to provide practical experience. While this review focuses on the full program, it’s also possible to audit individual courses for free. This flexibility allows learners to tailor their learning experience to their specific needs and interests.
There are also other alternatives for learning data engineering, such as the Google Cloud Professional Data Engineer Certificate and the Microsoft Certified Azure Data Engineer Associate program. Other relevant offerings can be found on platforms like edX, Udacity, and DataCamp. However, Coursera’s IBM Data Engineering Professional Certificate stands out for its comprehensive curriculum and hands-on approach to learning.
The IBM Data Engineering Professional Certificate is a beginner-level program that welcomes individuals from diverse professional and academic backgrounds. The program is designed to be accessible to anyone with basic IT literacy and an understanding of IT infrastructure. Familiarity with operating systems like Windows, Linux, or MacOS is required. While prior computer programming experience is not mandatory, it is stated in the course description that is beneficial (and in practice, I believe that you will struggle if you have no prior programming experience). Only high school mathematics should be needed for grasping the concepts covered in the program.
The program Is taught by a team of experienced instructors from IBM, ensuring that the content is up-to-date and relevant to the industry. The syllabus is fairly comprehensive, covering topics from introductory Python programming and Linux/UNIX shell scripts to relational databases, NoSQL databases, and big data technologies like Spark and Hadoop. The course culminates in a capstone project that allows learners to apply their knowledge to a real-world scenario.
How much does the Professional Certificate cost?
The IBM Data Engineering Professional Certificate is competitively priced, with a monthly subscription of $51 and a self-paced completion time of about five months. Overall, the program offers a valuable learning experience and is a worthwhile investment. If completing it at the recommended pace, the total cost is, in other words, $255.
Note, however, that this Professional Certificate is not included in Coursera Plus subscriptions but needs to be purchased separately. On the other hand, if you are on a budget, as it is self-paced, you can aim to complete the program in less than the recommended five months to save money. As for most Coursera courses, it is also possible to audit the individual courses of the Professional Certificate for free.
My overall impression
The IBM Data Engineering Professional Certificate provides a useful introduction to data engineering by incorporating a blend of video lectures, readings, quizzes, and hands-on projects to facilitate learning. These activities strike a balance between learning and application. Each course builds upon the previous one, ensuring a smooth learning progression.
The projects in the IBM Data Engineering Professional Certificate cover a wide range of data engineering tasks, including database design, querying diverse datasets, scripting file backups, optimizing data platforms, analyzing traffic data, working with NoSQL databases, training machine learning models, and designing data engineering platforms. These hands-on projects provide practical experience and reinforce the skills learned throughout the program.
The Professional Certificate is a 13-course series, and it is recommended to take the courses in the listed order to build on concepts taught in previous courses. Let’s discuss each course individually to explore its features and learning outcomes.
Detailed review: The component courses
Course 1: Introduction to Data Engineering
The IBM Data Engineering Professional Certificate begins with a comprehensive and high-level introduction to data engineering before delving into the more practical details. This course is designed to equip learners with an overview of the knowledge necessary for an entry-level role in this field.
The course is divided into four modules, each focusing on a different aspect of data engineering. It provides a clear understanding of the modern data ecosystem, the roles of various data professionals, and the key tasks involved in a data engineering lifecycle. It also introduces learners to various data repositories, ETL and ELT processes, data pipelines, and data integration platforms. Learners gain practical skills in Shell Script, Bash (Unix Shell), and Linux.
The course also includes hands-on labs that guide learners in creating an IBM Cloud Lite account, provisioning a database instance, loading data into the database instance, and performing basic querying operations.
Course 2: Python for Data Science, AI & Development
Following the introduction to data engineering comes an introduction to programming in Python. The course is designed for learners seeking to develop their skills in Python for real-world applications and offers a fairly comprehensive coverage of Python fundamentals and practical exercises using Jupyter Notebooks.
Taught by expert instructors from IBM, this course is divided into five modules, each addressing essential aspects of Python for data science and development. It begins by introducing learners to Python basics, covering data types, expressions, variables, and data structures. Through interactive exercises and quizzes, learners gain proficiency in mathematical operations, string manipulation, and efficient data storage.
In the second module, learners explore Python data structures, including lists, tuples, dictionaries, and sets to store and manipulate collections of data and handle complex datasets for data analysis tasks. Later it explores advanced Python concepts, such as conditions, branching, loops, functions, and exception handling for creating efficient programs and reusable code.
In the fourth module, learners focus on working with data in Python. They learn how to read and write files, manipulate data using popular libraries like Pandas and NumPy, and perform mathematical operations on datasets. The final module concentrates on collecting data through APIs and web scraping. Learners discover how to access web data, interact with APIs, and extract information from different file formats.
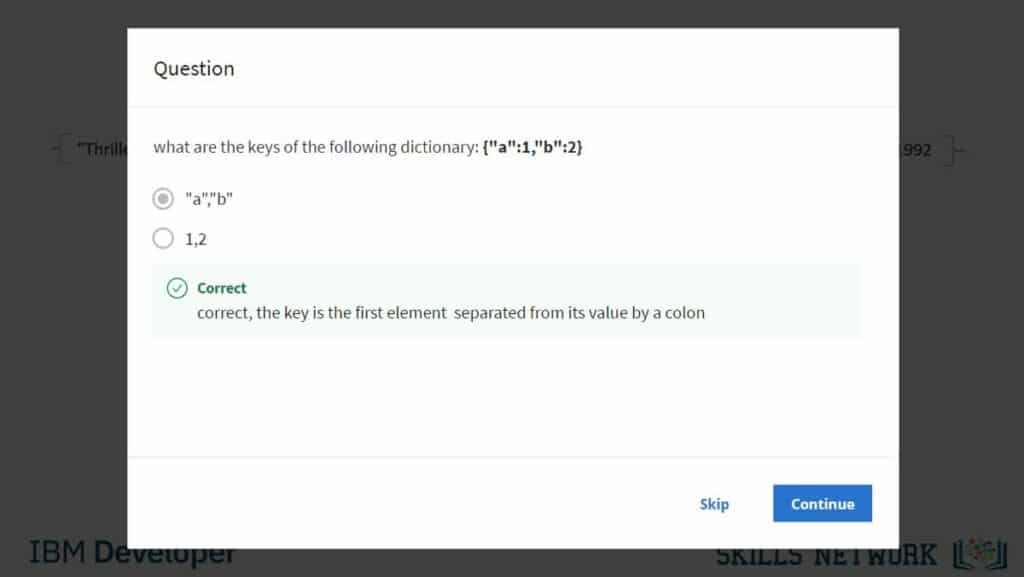
Course 3. Python Project for Data Engineering
A course designed to apply Python skills in real-world data engineering tasks; learners will have the opportunity to assume the role of a Data Engineer and work on a project that involves collecting, transforming, and loading data using Jupyter notebooks.
Before enrolling in this course, it is important to complete the prerequisite course “Python for Data Science, AI, and Development” to ensure a solid foundation in Python programming and data manipulation.

The course emphasizes practical application, introducing the Extract, Transform, Load (ETL) process, a fundamental concept in data engineering. Learners will learn how to read different file types, such as CSV and JSON, search for specific file extensions to extract data, and create a simple ETL program to transform and load data into a target file. These practical exercises provide a solid foundation for data management and manipulation. The course then progresses to more advanced techniques, such as web scraping and using APIs to extract data. Additionally, the course covers logging data using Python’s built-in logging module, ensuring data integrity and traceability throughout the ETL process.
Course 4: Introduction to Relational Databases (RDBMS)
After having familiarity with Python, it is time to introduce students to the world of relational databases. This 18-hour course focuses on equipping learners with the fundamental knowledge and practical skills needed to design and manage relational databases effectively.
Throughout the module, learners engage in practical exercises and real-world examples, allowing them to interact with popular relational databases such as MySQL, PostgreSQL, and IBM Db2. By working hands-on with these databases, learners solidify their understanding of database management principles. Learners explore data models, including schemas and tables, and learn how to create and design a relational database for specific use cases. The practical aspects of managing relational databases are emphasized, with a focus on using RDBMS GUI or web interfaces and executing SQL statements to create and manage tables. The module also delves deeper into the practical application of relational databases by exploring the features and functionalities of MySQL and PostgreSQL. Learners learn how to create databases and tables, define keys and constraints, and load data into the databases using these tools.
The module culminates in a capstone project that allows learners to showcase their acquired skills in a real-world scenario. In this project, learners design a database from a new dataset, employing techniques such as creating an Entity Relationship Diagram (ERD) to identify entities, attributes, and relationships. Additionally, learners demonstrate their ability to work with views, further showcasing their database management expertise.
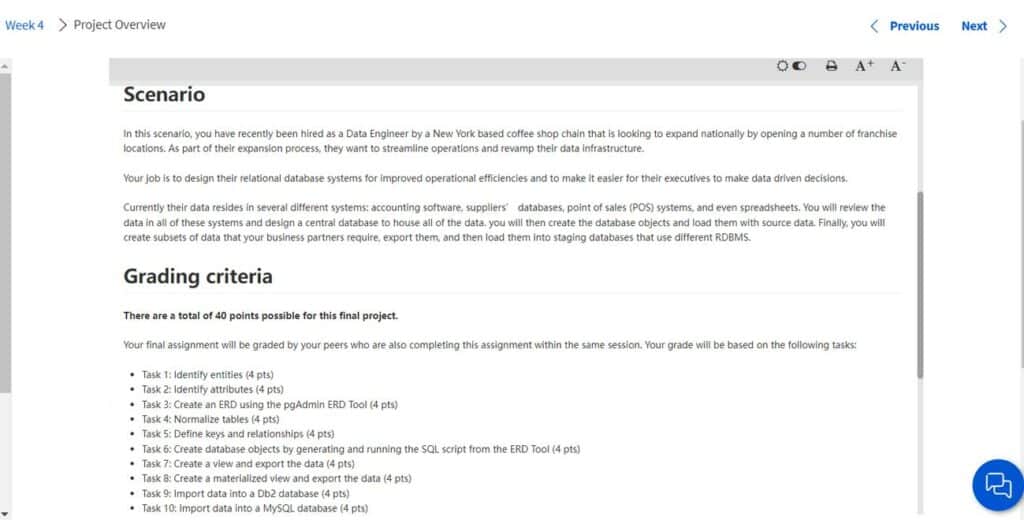
Course 5: Databases and SQL for Data Science with Python
Expanding on the previous module, this module delves deeper into SQL querying techniques and database administration. Learners gain proficiency in constructing complex SQL queries, using database functions, and working with stored procedures. Through practical labs and projects on Jupyter Notebooks with SQL and Python, they will work with real databases on the Cloud and apply their skills to real-world datasets.
Starting with the basics, the course covers SQL statements like SELECT, INSERT, UPDATE, and DELETE. They will also learn how to filter result sets using WHERE, COUNT, DISTINCT, and LIMIT clauses and differentiate between DML (Data Manipulation Language) and DDL (Data Definition Language) operations.
As the course progresses, learners will gain hands-on experience creating and manipulating tables, using string patterns and ranges for data searching, and sorting and grouping data in result sets. They will explore advanced concepts such as Stored Procedures, Views, ACID Transactions, and Inner & Outer JOINs, enabling them to tackle more complex data scenarios.
Course 6: Hands-on Introduction to Linux Commands and Shell Scripting
This module focuses on Linux commands and shell scripting, essential skills for data engineers working with data pipelines and automation. Learners gain hands-on experience navigating the Linux command line, writing shell scripts, and performing file operations.
This four-module course focuses on working with a virtual Linux server accessible through the web browser, which eliminates the need for downloading and installing software. It then provides information on how to use Linux terminal, execute commands, navigate directories, and edit files using popular text editors like Nano and Vim, along with a wide range of commands, including informational, file management, text processing, and networking commands.
Moreover, it emphasizes creating shell scripts that automate various tasks. Learners will gain knowledge about metacharacters, quoting, variables, command substitution, I/O redirection, pipes, and filters.
This module could benefit from more comprehensive explanations and examples to support learners with limited Linux experience. If that applies to you, I would recommend taking another introduction to Linux first.
Course 7: Relational Database Administration (DBA)
Focusing on the essentials for effective management of relational databases, the course delved into various aspects of database administration, including database creation, querying, configuration, and system object management. Emphasis is placed on practical database management tasks to ensure hands-on experience alongside theoretical understanding.
Key topics covered include database security, user authentication, role management, and object-level permissions. Learners explore how to automate functions like generating reports, notifications, and alerts using standard Linux and Unix shell commands. This practical approach enhances efficiency by streamlining routine tasks.
Its final project provides an opportunity to showcase skills in a real-world scenario. Learners engage in tasks such as database installation, configuration, user management, backup, recovery, indexing, optimization, and automation. This project serves as a comprehensive assessment of database administration abilities.
Course 8: ETL and Data Pipelines with Shell, Airflow, and Kafka:
With a focus on practical applications, this course revisits the two main approaches to data processing that were introduced in earlier courses to build data pipelines: Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT). Through real-world examples, learners gain insights into when to use each approach and their respective benefits. The course covers various methods and tools for data extraction, merging, and importing into data repositories. Additionally, learners learn how to define transformations to ensure data credibility, context, and accessibility.
Throughout the course, learners have the opportunity to explore key concepts such as batch and streaming data pipelines. The course also looks at the importance of parallelization and I/O buffers in mitigating bottlenecks and achieving optimal performance. The inclusion of Apache Airflow, a popular workflow management system, allows learners to understand the benefits of representing data pipelines as Directed Acyclic Graphs (DAGs). They learn to create tasks and operators using Airflow’s built-in functionality, enhancing the maintainability and collaboration of their data pipelines.
Another significant component of the course is Apache Kafka, an open-source event streaming platform. Learners discover the core components of Kafka, such as brokers, topics, partitions, producers, and consumers. They gain hands-on experience with Kafka Streams API, enabling them to process and analyze data in event streaming pipelines.
Course 9: Getting Started with Data Warehousing and BI Analytics
Focusing on data warehousing and business intelligence (BI) analytics, this module introduces learners to the concepts and methodologies involved in designing and deploying data warehouses. Learners explore tools like IBM Cognos Analytics and Tableau for creating interactive dashboards and visualizations. The module provides a solid foundation for leveraging data warehouses to drive insights and decision-making.
This course provides a comprehensive introduction to data warehousing systems, data marts, and data lakes, equipping learners with the necessary skills to design and populate data warehouses, model and query data using CUBE, ROLLUP, and materialized views, and create data visualizations using IBM Cognos Analytics.
Throughout this course, learners will dig into the architecture, features, and benefits of data warehouses, data marts, and data lakes. They will gain an understanding of how these entities contribute to effective data management and enable accurate and flexible reporting and data analysis for business decision-making. By exploring real-world use cases, learners will be able to apply their knowledge to practical scenarios. Additionally, this course introduces learners to popular data analytics and business intelligence tools, including IBM Cognos Analytics to create data visualizations and leverage the powerful features of IBM Cognos Analytics to gain insights from data.
The inclusion of a capstone project (for the course, not for the professional certificate as a whole) further enhances the learning experience. By completing this project, learners can showcase their acquired skills in data warehousing and BI analytics. This hands-on project allows learners to demonstrate their ability to design and implement various components in the data engineering lifecycle and apply their knowledge of relational databases, NoSQL data stores, big data engines, data warehouses, and data pipelines to solve real-world data engineering problems.
Course 10: Introduction to NoSQL Databases
This course provides learners with an in-depth understanding of NoSQL databases in the context of Big Data. Through hands-on experience with MongoDB and Cassandra, learners acquire essential skills for CRUD operations, data manipulation, and database management. The course differentiates the four main categories of NoSQL repositories and explores the advantages and challenges of distributed systems, offering insights into when to choose NoSQL over relational databases.
In the MongoDB section, learners delve into the characteristics and features of this popular document-oriented NoSQL database. They gain proficiency in CRUD operations, data sorting, indexing, aggregation, and advanced concepts like replication and sharing. The Cassandra section focuses on Apache Cassandra, known for scalability and high availability. Learners gain practical skills using the CQL shell, performing keyspace and table operations, and executing CRUD operations while considering consistency levels in distributed systems.
Upon completion, learners will possess a strong grasp of NoSQL databases and their applications. They will be equipped to make informed decisions on NoSQL usage and proficiently work with MongoDB and Cassandra. This course empowers learners to navigate the evolving Big Data landscape and harness the benefits of NoSQL technology.
Course 11: Introduction to Big Data with Spark and Hadoop
This course provides learners with an introduction to Big Data technologies, focusing on Apache Spark and Hadoop. Throughout the course, learners gain insights into distributed computing frameworks and develop essential skills for processing and analyzing large-scale data.
The course covers the fundamental concepts of Big Data, exploring its impact, use cases, tools, and processing methods. Learners gain a deep understanding of Apache Hadoop architecture, ecosystem, and practices, as well as Apache Spark and its capabilities in handling massive datasets.
Practical exercises play a crucial role in this course, allowing learners to set up a single-node Hadoop cluster using Docker, run MapReduce jobs, and gain hands-on experience with the Distributed File System (HDFS), MapReduce, HIVE, and HBase. Additionally, learners delve into the components of Apache Spark, including Resilient Distributed Datasets (RDDs), parallel programming, Spark SQL, and DataFrame queries. They explore Spark’s application submission, cluster management, and configuration options, equipping them with the skills to process and analyze large-scale datasets effectively.
By completing this course, learners develop a solid understanding of Big Data and its implications. They acquire the ability to leverage Hadoop and Spark for data processing, enabling them to extract valuable insights and make data-driven decisions.
Course 12: Data Engineering and Machine Learning using Spark
The course equips learners with essential skills to work with Apache Spark for data engineering and machine learning. It explores Spark Structured Streaming, GraphFrames, ETL processes, and the use of Spark MLlib for regression, classification, and clustering tasks. Prerequisite knowledge of Apache Spark and Jupyter Notebooks is recommended. Completion of the “Introduction to Big Data with Spark and Hadoop” course or equivalent is recommended before starting this course.
Starting with an introduction to streaming data and Spark Structured Streaming, learners understand how Spark handles real-time data for machine learning and AI tasks. They also explore graph theory and Apache Spark GraphFrames to identify suitable data for graph processing. ETL processes and integration of Spark MLlib for regression, classification, and clustering tasks are covered.
Hands-on exercises and labs enable learners to apply their knowledge in practical scenarios, working on real-world use cases and projects. By completing this course, learners gain valuable experience in data engineering and machine learning with Spark. They will be able to design and implement data engineering concepts and components, utilize ETL processes, apply Spark MLlib for machine learning tasks, and leverage Spark’s capabilities for data analysis and visualization.
Course 13: Data Engineering Capstone Project
The final course is the “Data Engineering Capstone Project,” which aims to bring together all of the courses of the IBM Data Engineering Professional Certificate to consolidate learners’ knowledge and skills. It presents a real-world data engineering scenario where learners, acting as Junior Data Engineers, apply their expertise in database management, ETL pipelines, and data analysis.
This project-based course is divided into modules that cover various aspects of the data engineering lifecycle. Learners design data platforms using MySQL and MongoDB, implement data warehouses, create reporting dashboards, perform ETL operations, analyze web server logs, and apply machine learning techniques for sales forecasting. Hands-on labs and quizzes accompany each module to reinforce understanding and skills.
By completing the final project, learners showcase their proficiency in essential data engineering skills and their ability to design and implement different data engineering components. They demonstrate knowledge of relational databases, NoSQL data stores, big data engines, data warehouses, and data pipelines. The inclusion of a peer-review process adds a collaborative and evaluative aspect to the learning experience.
What do others say?
Student reviews for the IBM Data Engineering Professional Certificate course on Coursera are predominantly positive. Learners commend the course for its hands-on nature, practical projects, and comprehensive coverage of data engineering concepts. Some participants mention the course’s challenging nature, especially for beginners, and suggest the need for more detailed explanations in certain modules. While there are concerns about limited instructor interaction, this is a common drawback of online courses.
Reviews on other platforms, such as Class Central and Reddit, echo similar sentiments, further emphasizing the program’s high ratings for its comprehensive curriculum and practical projects. While some learners highlight the significant time commitment required, they universally agree that the program’s value lies in the skills and knowledge gained. Several learners also attest to successfully transitioning to data engineering careers after completing the program. Overall, the IBM Data Engineering Professional Certificate receives positive feedback for its comprehensive curriculum, quality instruction, and practical learning experiences.
My recommendation
Coursera’s IBM Data Engineering is a meticulously organized professional certification program that equips learners with the essential skills and knowledge for a career in data engineering. As a participant in this course, I found the curriculum to be thoughtfully designed, providing a balanced blend of theoretical concepts and practical exercises. Although the program demands a significant time commitment, the knowledge and skills acquired throughout the course make it a valuable investment for individuals aiming to enter the field of data engineering or advance their existing careers.
One notable aspect of the program is its ACE recommendation, which allows participants to earn college credits upon completion. This recognition adds further credibility to the certificate and enhances its value for learners seeking academic recognition (only about 20 programs offered through Coursera are currently ACE-recommended). Additionally, the emphasis on hands-on activities and projects offers invaluable opportunities to apply newly acquired knowledge in real-world scenarios, boosting confidence and ensuring a deeper understanding of the subject matter.
Who is this program for?
While the program caters to beginners, it can be challenging for those with no prior experience in data engineering. However, the course material is presented in a manner that is accessible and engaging, providing ample support and guidance throughout the learning journey. Although some modules could benefit from more detailed explanations and increased interactivity, the overall value for money and the opportunity to establish a strong foundation in data engineering make the IBM Data Engineering Professional Certificate highly recommended for aspiring data engineers. Whether you are starting from scratch or looking to expand your skills, this program provides a solid platform to gain the necessary expertise and stand out in the competitive field of data engineering.
Get 40% off your first year of Coursera Plus Annual — unlimited access to 10,000+ courses (new subscribers only)
Read Next



Originally published July 28, 2023